Kaggle Titanic 1st Attempt
Billy Fung / 2015-10-30
Do Kaggle they said, it’s fun they said
After taking the online machine learning course with Andrew Ng on Coursera, I decided that after the course it would be best to do some more problems, and Kaggle is the idea place for it. One of the recommended beginner competitions is the Titanic one, where the data comes highly structured already in a nice format to work with. The goal is to predict who will survive and who won’t based on the given information that includes age, sex, cabin location, and more categories.
First attempt
I decided my first attempt would be a quick and easy to just see where I place amongst all the data science wizards. I decided the weapon of choice would be R, instead of my usual Matlab or Python, with a logistic regression model. Looking at the training data, the first thing I checked was for missing data, or NA values.
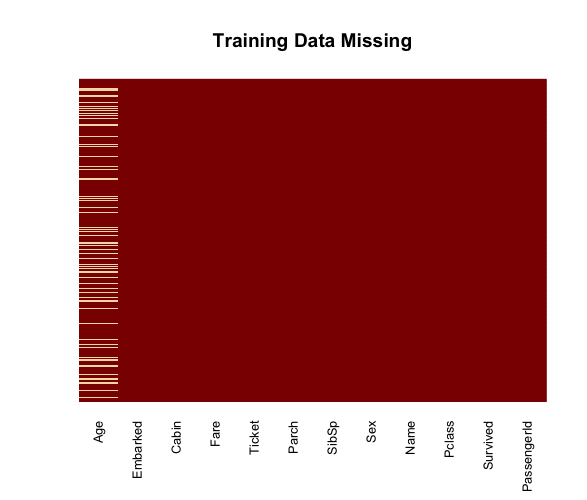
So with all those missing Age values, it would be best to fill them in. My
first attempt involved using the mice library for R, which stands for
multivariate imputation by chained equations.
library(mice)
imp.train <- mice(train, m=4)
train.complete <- complete(imp.train)
But this was horrendously slow and non-parallel for me, to the point where I thought it was my 6 year old laptop so I sent it over to a more powerful computer to try, and it was still really slow (more than 30s). I tried this for awhile, thinking it was something wrong with my computer or my data at first. There is an aspect of the data that makes it much more complex, which is the fact that trying to impute over factors in R means it will run through all the multiple levels in each factor.
Amelia
So with mice taking too long for my liking, I searched for another package to use that would hopefully be faster. I came across Amelia, not the pilot, and used that package to fill in my missing values. The package uses parallelization of cores to make computation much faster, and it seems like a more robust option compared to mice.
install.packages("Amelia")
library(Amelia)
#noms we care, ords we might care, idvars we dont care
noms <- c('Pclass', 'Sex', 'SibSp', 'Parch')
ords <- c()
idvars <- c('Name', 'Cabin', 'Embarked', 'Ticket', 'Fare')
a.out <- amelia(train, noms = noms, ords = ords, idvars = idvars)
imputedAge <- a.out$imputations$imp4$Age
As shown in my commented code, using Amelia is quite simple if the data itself
isn’t wide and this is just a preliminary analysis. Running the imputations
with Amelia, it will also display if a correlation matrix shows variables that
are highly correlated. After the computation, the summary of the Amelia object
will also display how much data was missing originally. In the case of the
training set, there was 0.1986532 fraction missing. After the imputation, I
put the filled in ages into the training dataframe and continued with my model
creation.
Logistic Regression
This is the simpliest (that I could think of) implementation-wise in R, so that is why I decided to use it. Lousy reason I know. So running logistic regression on Age, Sex, and PClass, my first Kaggle score placed me somewhere around 3000th place in the competition. Out of 3500. Based on the markers that Kaggle placed, my model was better than predicting all deaths.
model <- glm(Survived ~ Age + Sex + Pclass, family = binomial, data=train)
glmPredict <- predict(model, newdata=test, type = "response")
Without doing a proper statistical evaluation of my model, this is a pretty decent result I’d say. I always like to start with a rough, unrefined model baseline just so I know that if future models get worse than this, then that means I’ve done something wrong. My accuracy on the test set was 0.75598.
Future improvements
After doing this rough logistic regression model, some changes for the future would be to look at using some more of the data columns, and perhaps extract more information out of the data. Another one might be to perhaps convert the Sex observation to a binary value which might help yield better results. I also think that I vaguely recall learning that logistic regression works best with numerical observation values. Another thing would be to split the training data into training and cross validation, so then I can test the model on the cross validation set before using it on the test set. ROC checking!
All these things for next time, and maybe even implementing a different classification method (trees?).