Tell Me About Coffee
Billy Fung / 2016-01-22
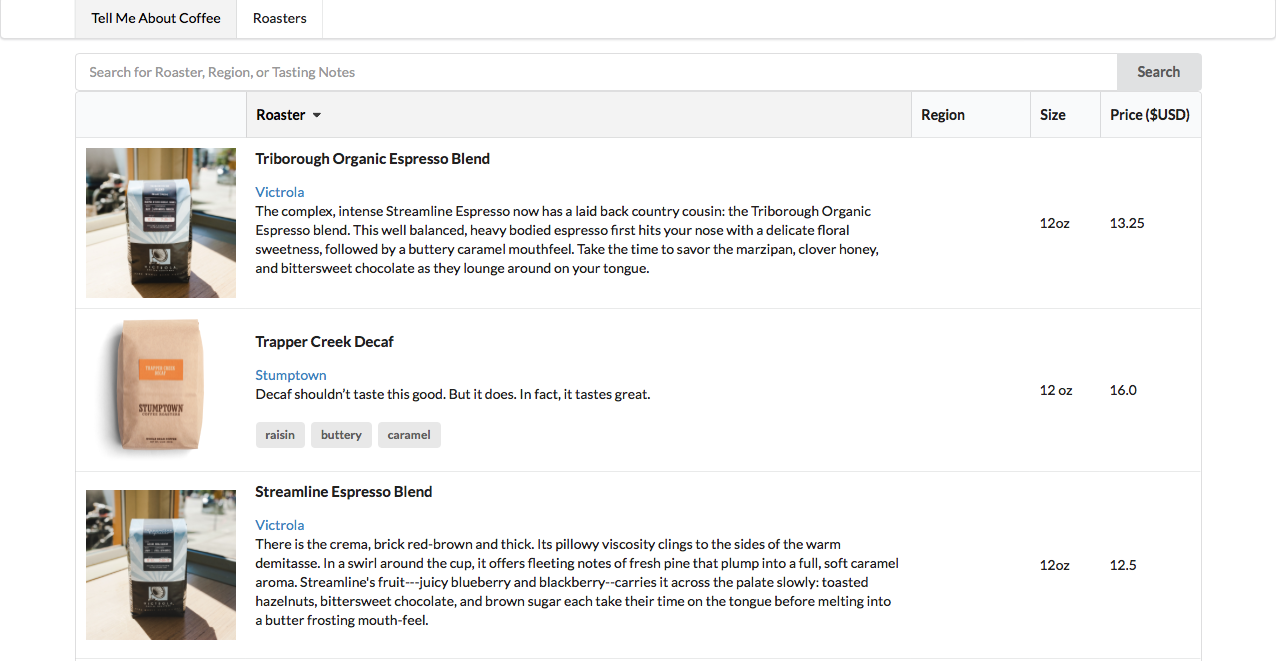
The project I’ve been working on in my spare time for the past 2 weeks is finally deployed and up at tellmeabout.coffee. I made the site with my friend Jin, or rather he kind of told me to make it as a learning experience. The essential functionality is that we wanted a website to display information about available coffees from different roasters. Currently the information is limited to 3 roasters, but that was because we didn’t want to spend too much time writing scrapers and wanted to get a working website up.
Backend - Flask
The backend of the site is made using Flask, because of it’s minimal features, and because I wanted to get more experience with Flask. In this age, there are so many choices for frameworks (and microframeworks) that it’s easy to get flustered trying to decide on one to use. Since I had used Flask and Google App Engine before, I decided to use it again and expand my knowledge. The last time I used it, it was a very basic proof of concept for controlling a robotic arm over the web. So this time I decided to make a web application that was more complete, with a better frontend. I’m still not comfortable calling myself a full stack developer, but the coffee project was a great way for me to learn about all the different aspects of the stack in Flask.
Scraping and cron jobs
I’ve become quite comfortable scraping in Python, so scraping coffee data from
various roasters wasn’t too difficult, although still a chore as usual when
you encounter irregular schema. Google App Engine gives you the ability to
schedule cron jobs, which is essentially setting a schedule where the
server runs a script for you at intervals. This allows for updating of the
coffee database regularly in order to keep the website up to date. Apart from
following the documentation and editing the app.yaml and cron.yaml,
routing the address within the Flask app is required. This is done as follows:
@app.route('/cron/scrape_all')
def cron_scrape():
try:
# run whatever you want here
scrapers.scrape_intelli()
scrapers.scrape_victrola()
scrapers.scrape_stumptown()
except Exception as e:
logging.warning("Error: {}".format(e))
return "Finished scraping"
To run either the scrapers individually or to test the cron job, the Google App Engine (GAE) local server gives an admin console to do so. To run the scripts individually, there is an interactive console that will let you import your functions and then run them to fill the database. The cron jobs tab will allow you to test your cron job to make sure all the configurations are correct before deployment.
Google NBD datastore
With the scraped data from the roasters, Google App Engine gives a couple of options for storing data. I will preface this by saying that I am no expert in databases, with only really some theoretical knowledge and then some usage of PostgreSQL. So for the purposes of this coffee website, the Google NBD datastore did all I asked it to do. The model had some floats, mostly strings, a boolean, a date, a blob (for the images), and a list. The only thing I didn’t really like was that I had to use a proprietary database that Google provided. Since I wasn’t doing anything complex with the databse,
The basics to storing data is that there is a ndb.Model object, then you
pass the model whatever data you want to store. After that, you give the
command put() and the data is stored in the database. Of course this is a
very basic behavior, but I didn’t run into any problems with it.
coffee=Coffee(**coffee_data)
try:
coffee.put()
Running the GAE server locally, you can enter into the admin console to view the entities in the datastore. This will let you confirm that data.
Frontend
So frontend is the stuff I’m very inexperienced in, which was one of the main things I wanted to work on. For the very basic, functional website that is up right now, there isn’t anything fancy involved yet. Having used Bootstrap before, I decided to try another framework, namely Semantic UI. One of the main differences I found is that Semantic isn’t as popular, so plugins aren’t as available sometimes. Or they just haven’t been tested for Semantic.
In order to keep things as basic as possible for now, the design consists of a
sortable table and a search bar. The search bar filters the table for
specific words. Right now I think that the basic functionality is there, but
there is of course much to improve on. I definitely plan on adding more
features soon, such as perhaps a map to search for regions of coffee.
JQuery tablesorter
The bulk of the work involves taking JQuery plugins that already exist and then making them work the way I want. One of the plugins used for frontend table sorting is the very popular tablesorter. The plugin is very feature filled, but all I needed it to do was to sort the table of coffees based on a specific value. Since the layout of my table has the coffee name, the coffee roaster, the coffee description, and the coffee tasting notes all within one cell, it’s not a traditional table. So a bit of modification was needed in order for the tablesorter to sort just by coffee roaster; setting a target for text extraction is how it was done.
The other client-side sorting involved using the search bar to search for either coffee roaster, region, or a tasting note. Again, using the same JQuery plugin but with a filter add-on did the job. Largely the frontend stuff is still a bit of a magical experience for me, but it is definitely something I would like to work on more.
Future plans
The plan is to involve more filtering and a cleaner design of the page so that as more roasters are added, users could choose certain roasters to filter by and then search for tasting notes between them. Or perhaps have an account where users can save preferences and then when they visit the website again, they are notified of new coffees.