Web Scraping and PostgreSQL
Billy Fung / 2016-01-28
PostgreSQL and Python scraping
Been meaning to learn Python programming? Want to see what the hype around PostgreSQL is all about? Well the best way to do both is to dive right into it with a scraping project. Following along, you’ll learn the basics of running a web scraper on a website to gather information and then put that information into a database where you will be able to make useful queries from.
[PostgreSQL][2] has been touted as the “world’s most advance open source database”, and offers various features that make it stand out from other SQL databases such as MySQL and MariaDB. Although users might not immediately make use of those features, it is good to start with a database that has those features available if needed in the future. With a database chosen, the next step is to fill the database with data. It doesn’t really matter if you choose a database first or the data first, what is important is that you choose the tool that gets the job done.
The data
Scraping data from a website is a way to take information available online, and then either manipulate it immediately, or store it in a database for future functionality. In this example, the data will come from an audition and jobs site, StarNow which allows models and photographers to advertise their talent. Exploring the website, model profiles include a plethora of data, ranging from acting and model credentials, to physical details of the model. Depending on how much data you want, and the goals of your project, you can choose to scrape all the data available, or just a small subset to make the job quicker. Here the goal will be to scrape all the physical attributes of models, and then put those attributes into a PostgreSQL database, using Python.
Creating the database
Following the installation instructions from the PostgreSQL website for
your OS, the first step is to create the database, either locally or in the
cloud with Compose.io. In order to create a new database, you must first
connect to the default postgres database and then run the command CREATE
DATABASE starnow. Now there will be a starnow database available locally
(or on the cloud), and with that you will be ready to start putting data into
it. Alternatively, this can also all be completed within a Python script with
the psycopg2 library. This library is an adapter layer that allows Python
to communicate with the Postgres database.
from psycopg2 import connect
from psycopg2.extensions import ISOLATION_LEVEL_AUTOCOMMIT
con = None
# connect to the default admin database
con = connect(database='postgres')
dbname = "starnow"
# autocommit ends transaction after every query
con.set_isolation_level(ISOLATION_LEVEL_AUTOCOMMIT)
cur = con.cursor()
cur.execute('CREATE DATABASE ' + dbname)
cur.close()
con.close()
Scraping the data
Beautiful Soup is a Python library for scraping and parsing, and although other Python scraper libraries exist, this one is very well documented and easy to use. Along with the requests library for HTTP communication, these two tools are the bread and butter of Python scraping for projects that aren’t too complex. Other options will be discussed later. The general scraping process is then: 1. request search page 2. scrape search page for models 3. request model page 4. scrape model page for physical attributes 5. repeat for all models on current search page 6. scrape next search page till no more search pages
The data fields that are available on the profile pages on StarNow are limited
to: variables = ['name', 'gender', 'location', 'username', 'talenturl',
'roles', 'height', 'hips', 'weight', 'shoe', 'ethnicity', 'hair', 'skin',
'hairlength', 'eye', 'hairtype', 'chest', 'dress', 'waist']
These variables will then become the columns for the physical table within
the starnow database.
CREATE TABLE physical (id serial PRIMARY KEY, name varchar, gender varchar,
location varchar, username varchar, talenturl varchar, roles varchar, height varchar, hips varchar,
weight varchar, shoe varchar, ethnicity varchar, hair varchar, skin varchar, hairlength varchar, eye varchar, hairtype varchar, chest varchar,
dress varchar, waist varchar)
This will create a table called physical with all the variables in lower
case as type varchar. If you want to use case sensitive column names, enclose
the variable in “, eg. ‘Name’ varchar. For the ease of putting data into the
database quickly, the types were all chosen to be varchar, meaning Python
strings.
The lazy method of scraping the results page is to first look at how many
results pages there are, in this instance the last page is 3528. Knowing this,
iterating requests through all the results pages is then: import requests
from bs4 import BeautifulSoup for x in range(1, 3528): searchPage =
"http://www.starnow.com.au/talent/?p=%d" % x # grab html and then use bs4 to
parse try: r = requests.get(searchPage) soup = BeautifulSoup(r.content)
except: print "Error getting page " + searchPage pass
Parsing with Beautiful Soup
Each search result page returns 20 different profiles; the next step is then to identify how each profile in the HTML source. This is often the part where scraping data gets messy and dirty, sometimes website don’t have logical coding styles or naming patterns and it will be left to the scraper to dig through it all. Luckily with StarNow the code is nicely tagged, so each of the 20 ads on the result page can be obtained by
soup.find_all("div", {'itemtype': ['http://schema.org/Person']})
which gives a Python list of 20 results. The next step is to request the model
page, which is easily done once the username is obtained for talent in
directory: # go through the 20 ads and parse within them # username in <a
href=""> data['name'] = talent('a')[0]['href'][1:] data['url'] =
"http://www.starnow.com.au/" + data['name'] try: personalPage =
requests.get(data['talenturl']) personalSoup =
BeautifulSoup(personalPage.content) except: print "error getting model page" +
data['talenturl'] pass
Once the model’s profile page is obtained, you can begin looking for the data
that fills the table. A very handy feature of BeautifulSoup is the find
function, which allows you to search through the document for certain html
tags. The ['content'] gives the contents within the tag that BeautifulSoup
finds
data['gender'] = soup.find('meta', {'property':'gender'})['content']
data['name'] = soup.find('meta', {'property':'name'})['content']
data['location'] = soup('span')[2].string.strip()
data['username'] = soup.find('meta',{'property':'profile:username'})['content']
data['roles'] = soup.find_all('div', {'class': 'profile__roles'})[0].string.strip()
The physical details are located within a table, but BeautifulSoup makes it
easy to find. physical = soup.find('table', id='ctl00_
cphMain_physicalDetails_memberAttributes') With the physical details table
HTML, the rest of the data for the database table can then be filled in using
a simple iteration.
# create a dict mapping the db column names to search terms
searchword = {'height':'Height:', 'hips':'Hips:', 'weight':'Weight:', 'shoe':'Shoe size:', 'ethnicity':'Ethnicity:',
'hair':'Hair color:', 'skin':'Skin color:', 'hairlength':'Hair length:', 'eye':'Eye color', 'hairtype':'Hair type:',
'chest':'Chest:', 'dress':'Dress Size:', 'waist':'Waist:'}
if 'Model' in data['roles'] or 'Actor' in data['roles']:
for x in searchword.keys():
try:
data[x] = physical('div', text=re.compile(searchword[x]))[0].next_sibling.strip()
except:
pass
Putting the data into the database
Once all the data is collected, you are ready to put it into your PostgreSQL database. The psycopg2 library makes this easy once again
try:
conn = psycopg2.connect(database="starnow")
cur = conn.cursor()
except:
print "Unable to connect"
cur.execute("INSERT INTO starnow (%s) VALUES (%s)" %(','.join(data), ','.join('%%(%s)s' % k for k in data)), data)
# don't forget to commit to make changes persistent
conn.commit()
That last step had a bit of weirdness going on with the INSERT statement,
but all it does is go through the dict data, and then format it into such a
way so that the SQL command will be executed without SQL injections. The
longer way would be to have an insert statement for every item within the data
dictionary. Now all the data is in your starnow database!
Querying
Well with all that data in your database, what do you want to do with it? Fear
not, querying it with psycopg2 is also very simple. Website searches often let
you filter by gender, and that looks like: cur.execute("SELECT * FROM
starnow WHERE gender='Male'") male = cur.fetchall() And with that you have
all the scraped male models ready for whatever purposes you’d like.
Using numpy and matplotlib you can create simple histograms to look at
distributions.
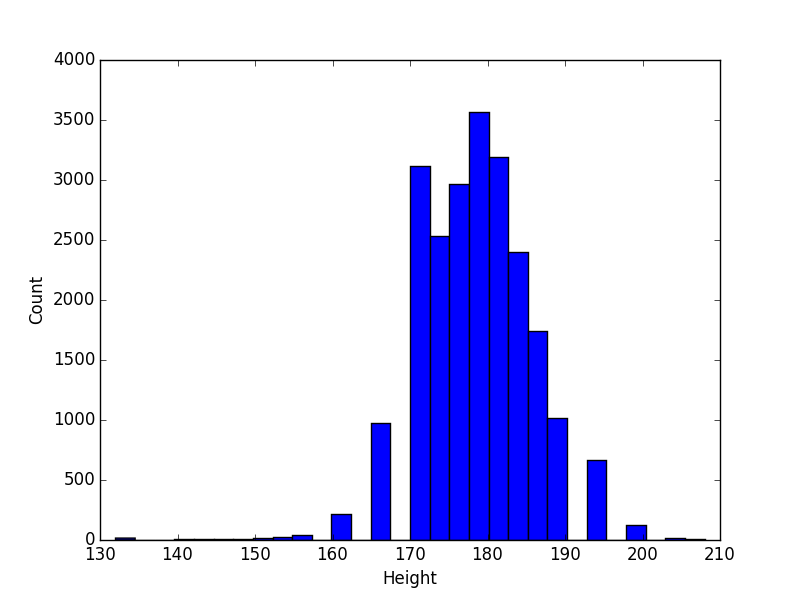 A simple histogram showing the distribution of male model
heights on StarNow.au
A simple histogram showing the distribution of male model
heights on StarNow.au
What next?
Well that sums up a very simple and quick intro to scraping with Python, BeautifulSoup4 and PostgreSQL. As stated earlier, this is only one of the many options available to you for scraping; the same results could easily have been accomplished using Python with Scrapy and SQLite. With all this physical details data, you can now do lots of fun stuff like create recommendation engines based off physical details, look at the statistics for models in the database, create your own search engine app for the database, the list goes on. Having a database and querying it is the framework of most online web applications these days. If you want to do more, creating more tables within the database for more data like the acting and modeling credentials is good practice as well.